
関連
- GCP CLI設定 CloudFunctions+BigQuery+CloudRun+ESPv2+独自ドメイン①
- GCP BigQueryの作成 CloudFunctions+BigQuery+CloudRun+ESPv2+独自ドメイン②
- GCP CloudFunction 関数の作成 CloudFunctions+BigQuery+CloudRun+ESPv2+独自ドメイン③
- GCP CloudRun + ESPv2によるAPI Gatewayリバースプロキシの作成④ CloudFunctions+BigQuery+CloudRun+ESPv2+独自ドメイン
データセット └ テーブル・ビュー
データセットはコンテナのようなもの
テーブルの確認
% bq ls -p
projectId friendlyName
------------------------------- -------------------------------
test-cloud-functions-20211208 test-cloud-functions-20211208
データセット作成
$ bq mk test_dataset_kanehiro Dataset 'test-cloud-functions-20211208:test_dataset_kanehiro' successfully created.
テーブルの作成
login_histories.json
[
{
"name": "user_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "anonymous_token",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "login_type",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "created_at",
"type": "TIMESTAMP",
"mode": "REQUIRED"
}
]
変数定義
PROJECT_ID=test-cloud-functions-20211208
DATASET=test_dataset_kanehiro
TABLE_NAME=${DATASET}.login_histories
テーブル作成
- created_atに日別でPartitioning
- user_idでclustering_fields指定
$ bq mk \
--project_id=${PROJECT_ID} \
--schema login_histories.json \
--time_partitioning_type=DAY \
--time_partitioning_field=created_at \
--clustering_fields=user_id \
--use_legacy_sql=false \
--table ${TABLE_NAME}
Table 'test-cloud-functions-20211208:test_dataset_kanehiro.login_histories' successfully created.
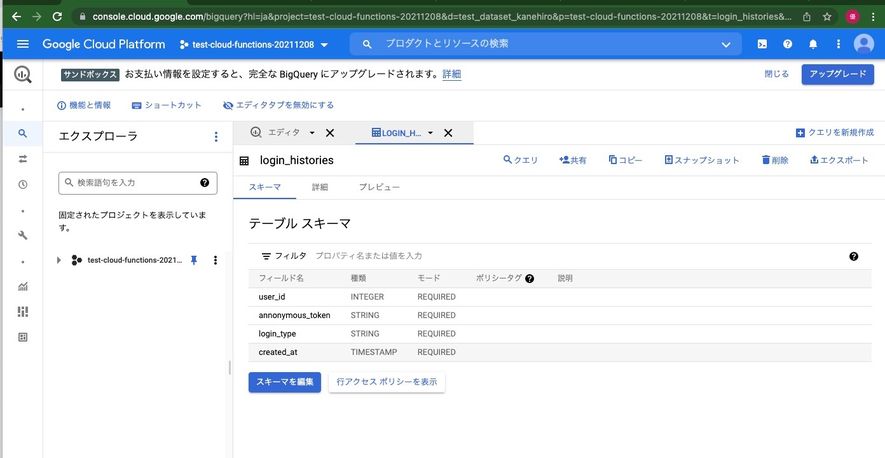
% bq show test_dataset_kanehiro.login_histories
Table test-cloud-functions-20211208:test_dataset_kanehiro.login_histories
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Labels
----------------- ---------------------------------------- ------------ ------------- ----------------- ------------------- ------------------ --------
08 Dec 17:07:11 |- user_id: integer (required) 0 0 06 Feb 17:07:10
|- annonymous_token: string (required)
|- login_type: string (required)
関連記事 - More from my site -
 PHP Cache_Lite
PHP Cache_Lite PHP 線形探索(リニアサーチ)
PHP 線形探索(リニアサーチ) 加法定理 証明
加法定理 証明 【Solved】Mac UPSB(MacBookPro14,X): thunderbolt power on failed
【Solved】Mac UPSB(MacBookPro14,X): thunderbolt power on failed FuelPHP Twig テンプレートエンジン導入
FuelPHP Twig テンプレートエンジン導入 最短経路 順列
最短経路 順列 Windows ファイルの比較 WinMerge
Windows ファイルの比較 WinMerge Laravel ポケモンでリポジトリパターン
Laravel ポケモンでリポジトリパターン Vagrant Virtualbox
Vagrant Virtualbox さくらのメールボックスの利用する為のDNSレコード
さくらのメールボックスの利用する為のDNSレコード PostgreSQL チューニング pgtune
PostgreSQL チューニング pgtune PHP ボゴソート Bogo Sort
PHP ボゴソート Bogo Sort IAM, 操作履歴の検索
IAM, 操作履歴の検索 【Munin】 MySQL InnoDB free tablespace UNKNOWNs: Bytes free is unknown.
【Munin】 MySQL InnoDB free tablespace UNKNOWNs: Bytes free is unknown.